Objective
Before we begin, I would like to acknowledge that the framework for this analysis was adapted from a blogpost found on the wonderfully interesting R-bloggers website. The objective of this analysis is to use sentiment analysis on different religious texts to visualise the differences/ similarities between them. This concept is of course fraught with a host of issues. Not least of which being detractors who will likely not endeavour to engage in rational debate against the findings of this work. This is of course beyond the control of the experimental design so I rather focus here on the issue that the translations of the texts used are not modern, and none of them were written (and generally not intended to be read in) English. Therefore a sentiment analysis of these works will be given to a certain amount of inaccuracy because the sentiment database is a recent project and one must assume that the emotions attached to the words in the English language reflect modern sentiment, and not the emotive responses that were necessarily desired at the time of writing/ translation. That being said, the sentiment that these texts would elicit in a reader today (assuming that anyone actually still reads the source material for their faith) would be accurately reflected by the sentiment analysis project and so this issue is arguably a minor one. As a control group (non-religious text), we will be using Pride and Prejudice, by Jane Austen simply because this has already been ported into R and is readily accesible in the package janeaustenr.
For more information on the sentiment analysis project one may find the home page here.
Text Downloads
The following links were used to download the religious texts used in this analysis:
I generally used the first link that DuckDuckGo provided when searching for pdf versions of these books. If anyone knows of better sources for these texts please let me know and I would be happy to update the data source.
Packages
The packages required to perform the following analysis
library(pdftools)
library(tidyverse)
library(tidytext)
library(janeaustenr)
library(heatwaveR)
Analysis
First we convert the PDF’s to text and merge them.
## Load the texts
# Pride and Prejudice
pride <- tibble(txt = prideprejudice,
src = "pride")
# Quran
quran <- tibble(txt = as.character(pdf_text("../../static/data/EQuran.pdf")),
src = "quran")
# Bible
bible <- tibble(txt = as.character(pdf_text("../../static/data/KJBNew.pdf")),
src = "bible")
# Torah
torah <- tibble(txt = as.character(pdf_text("../../static/data/Torah.pdf")),
src = "torah")
# Bhagavad Gita
gita <- tibble(txt = as.character(pdf_text("../../static/data/BGita.pdf")),
src = "gita")
# Book of the dead
dead <- data_frame(txt = as.character(pdf_text("../../static/data/EBoD.pdf")),
src = "dead")
# Combine
texts <- rbind(pride, quran, bible, torah, gita, dead)
Then we must download the NRC Word-Emotion Association Lexicon(Mohammad and Turney 2013).
# Note that this will require you to agree to term of use
nrc_sentiment <- get_sentiments("nrc")
nrc_sentiment <- readRDS("../../static/data/nrc_sentiment.Rds")
After loading and merging the texts we want to run some quick word counts on them.
# Total relevant words per text
total_word_count <- texts %>%
unnest_tokens(word, txt) %>%
anti_join(stop_words, by = "word") %>%
filter(!grepl('[0-9]', word)) %>%
filter(!grepl('www.christistheway.com', word)) %>%
left_join(nrc_sentiment, by = "word") %>%
group_by(src) %>%
summarise(total = n()) %>%
ungroup()
# Total emotive words per text
emotive_word_count <- texts %>%
unnest_tokens(word, txt) %>%
anti_join(stop_words, by = "word") %>%
filter(!grepl('[0-9]', word)) %>%
filter(!grepl('www.christistheway.com', word)) %>%
left_join(nrc_sentiment, by = "word") %>%
filter(!(sentiment == "negative" | sentiment == "positive" | sentiment == "NA")) %>%
group_by(src) %>%
summarise(emotions = n()) %>%
ungroup()
# Positivity proportion
positivity_word_count <- texts %>%
unnest_tokens(word, txt) %>%
anti_join(stop_words, by = "word") %>%
filter(!grepl('[0-9]', word)) %>%
filter(!grepl('www.christistheway.com', word)) %>%
left_join(nrc_sentiment, by = "word") %>%
filter(sentiment == "positive" | sentiment == "negative") %>%
group_by(src, sentiment) %>%
summarise(emotions = n()) %>%
summarise(positivity = emotions[sentiment == "positive"]/ emotions[sentiment == "negative"]) %>%
ungroup()
# Combine
word_count <- cbind(total_word_count, emotive_word_count[2], positivity_word_count[2]) %>%
mutate(proportion = round(emotions/total, 2))
# Lolliplot
ggplot(data = word_count, aes(x = as.factor(src), y = proportion)) +
geom_lolli(colour = "black") +
geom_point(aes(colour = positivity)) +
geom_text(aes(y = 0.45, label = paste0("n = ", total))) +
scale_y_continuous(limits = c(0,0.5), expand = c(0, 0)) +
scale_color_continuous("Proportion of\nPositivity", low = "navy", high = "pink") +
labs(x = "Text", y = "Proportion of Emotive Words")
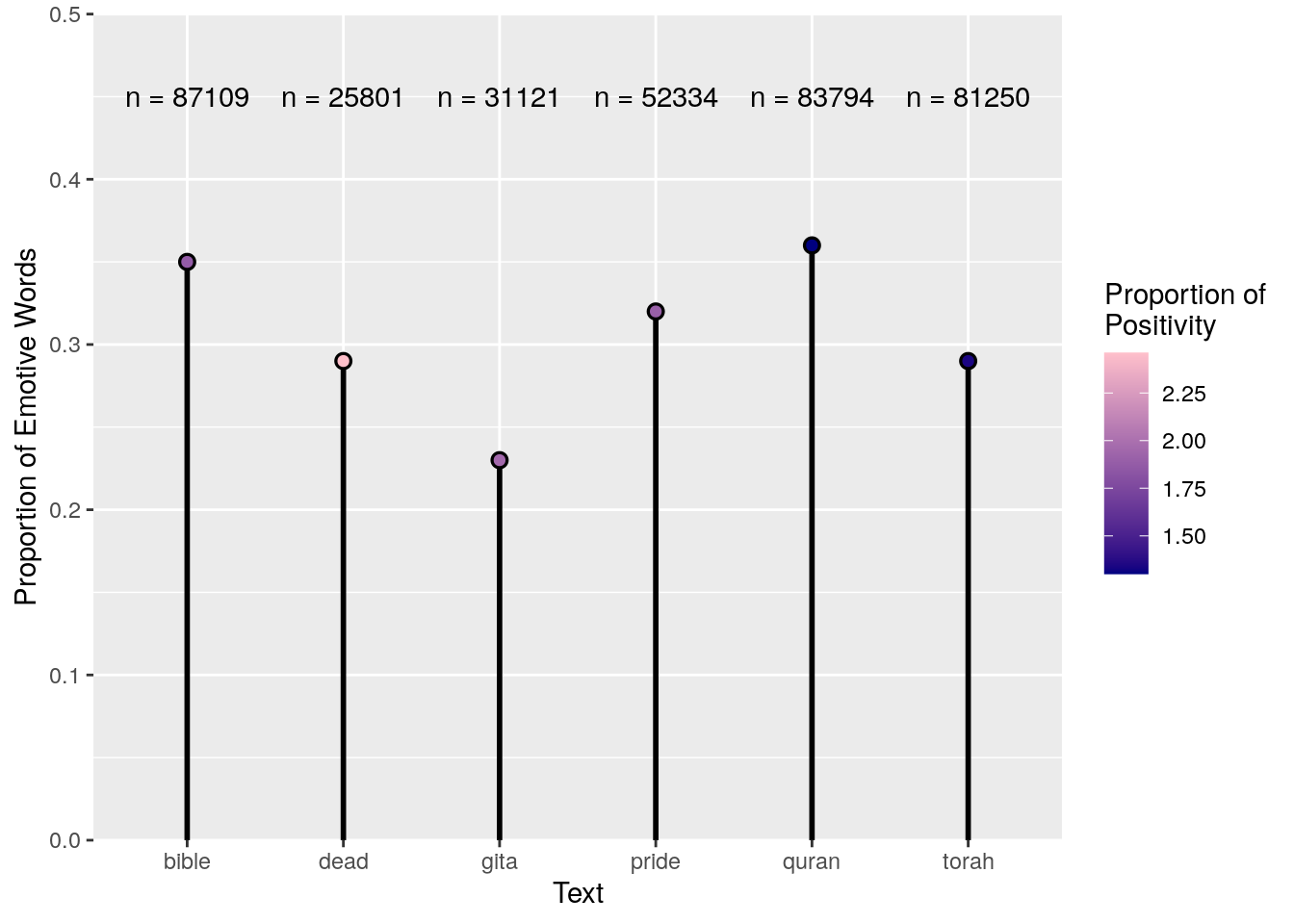
Figure 1: Proportion of emotive words in each text to their total word counts (shown in red).
I find it somewhat surprising that The Egyptian Book of the Dead would have the highest proportion of positive sentiment to negative sentiment.
But let’s take a more in depth look at the sentiment for each text.
# Calculate emotions
emotions <- texts %>%
unnest_tokens(word, txt) %>%
anti_join(stop_words, by = "word") %>%
filter(!grepl('[0-9]', word)) %>%
filter(!grepl('King James Version of the New Testament - ', word)) %>%
filter(!grepl('www.christistheway.com', word)) %>%
filter(!grepl('BHAGAVAD GITA', word)) %>%
left_join(nrc_sentiment, by = "word") %>%
filter(!(sentiment == "negative" | sentiment == "positive")) %>%
group_by(src, sentiment) %>%
summarize(freq = n()) %>%
mutate(proportion = round(freq/sum(freq),2)) %>%
# select(-freq) %>%
ungroup()
# Boxplot
ggplot(emotions, aes(x = sentiment, y = proportion)) +
geom_boxplot(fill = "grey70") +
geom_point(aes(colour = src), position = "jitter", size = 2) +
labs(x = "Sentiment", y = "Proportion", colour = "Text")
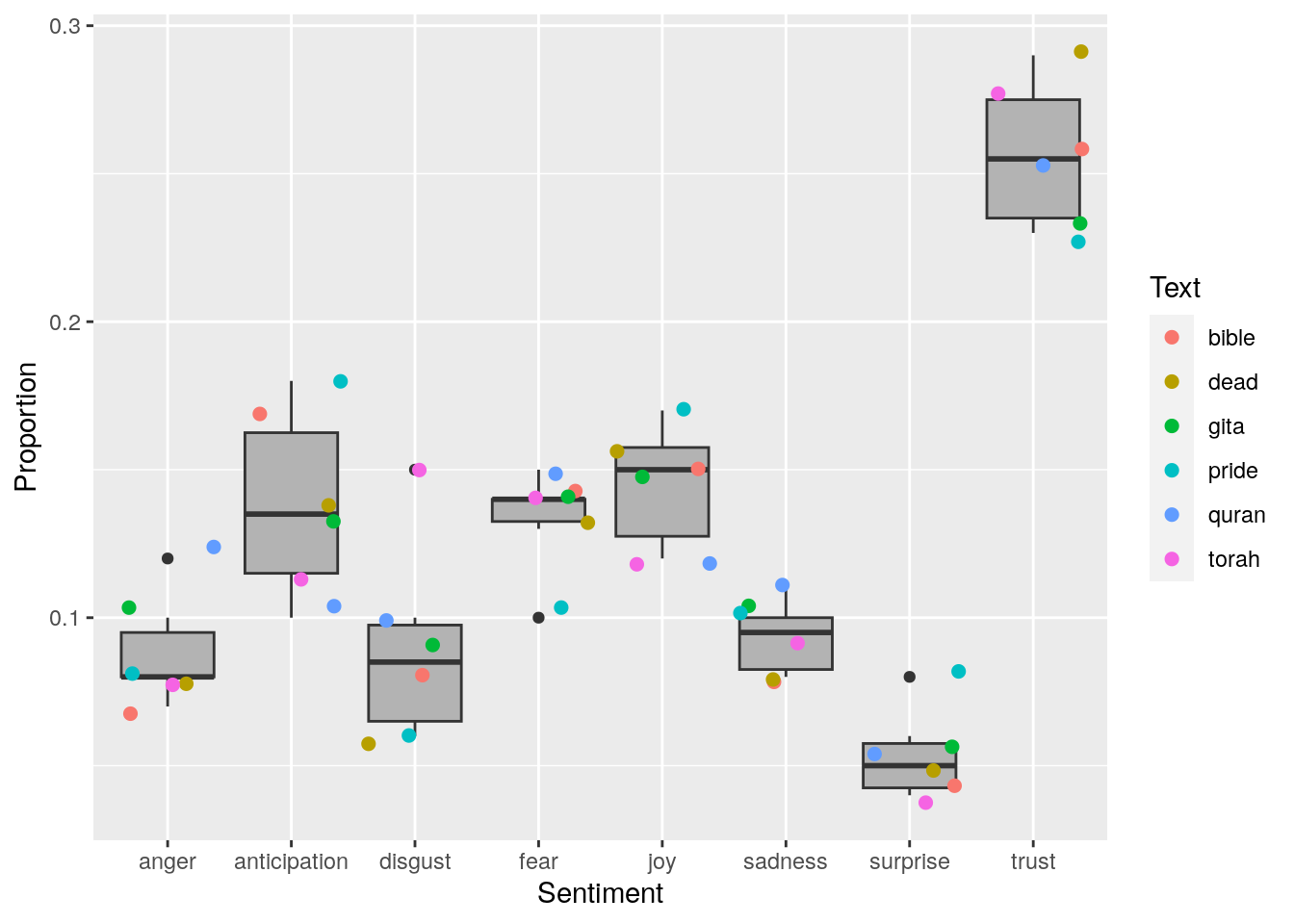
Figure 2: Boxplots of emotion for the texts. Individual scores shown as coloured points.
ggplot(emotions, aes(x = sentiment, y = proportion)) +
geom_polygon(aes(fill = src, group = src), alpha = 0.8, show.legend = FALSE) +
coord_polar() +
scale_y_continuous(limits = c(0, 0.3)) +
facet_wrap(~src) +
labs(x = "", y = "")
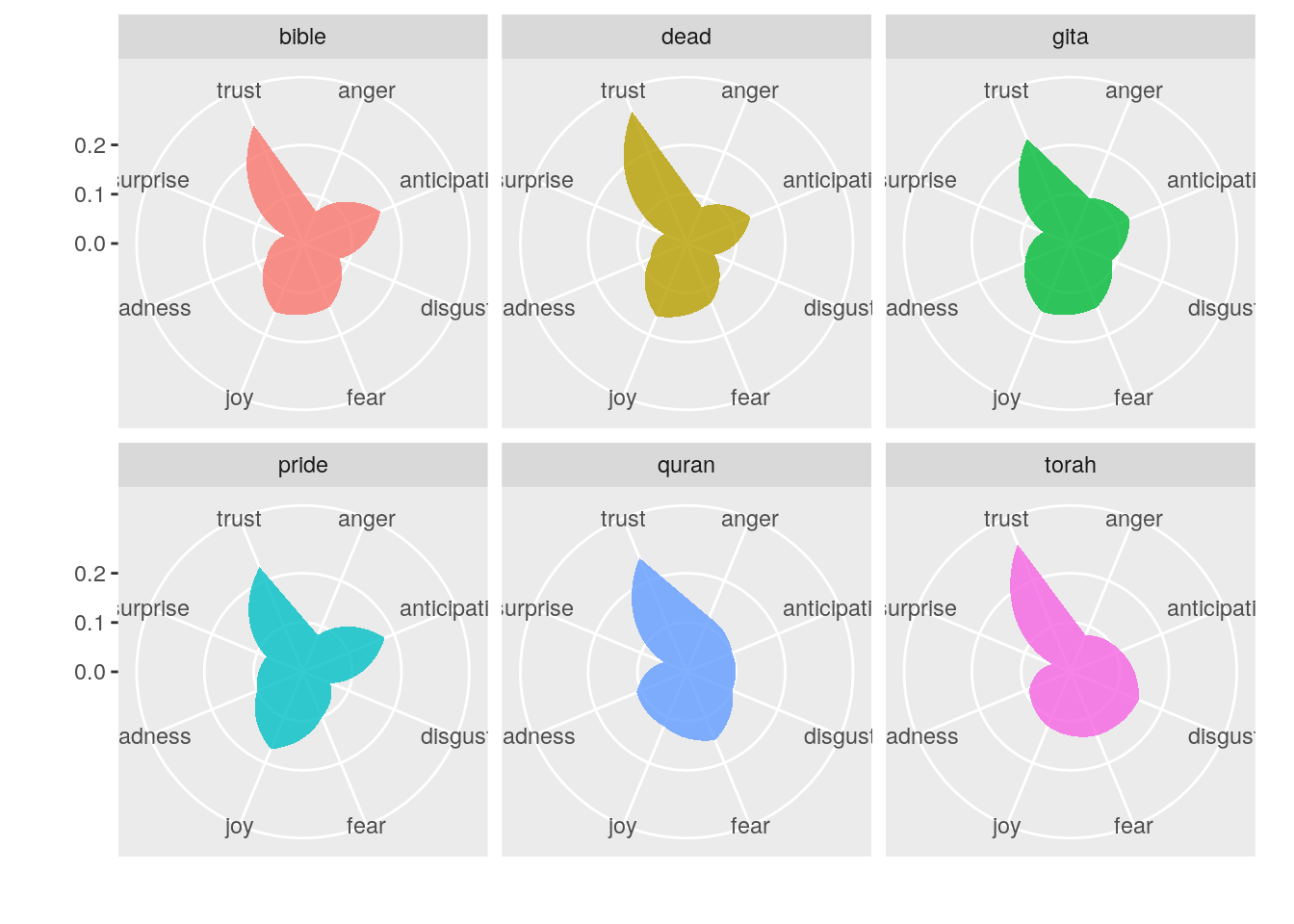
Figure 3: Frequency polygons of the proportion of emotions for each text shown in facets.
Results
The frequency polygons shown here most notably outline that all of the texts emphasise trust over anything else. Another interesting pattern is the lack of surprise employed in the texts. The Bhagavad Gita seems to have the smoothest distribution of emotion, with the Quran perhaps coming in second. I found it odd that a novel, Pride and Prejudice, would employ a higher proportion of joyous sentiment than the religious texts against which it was compared. The Quran just barely nudges out the Bhagavad Gita to come out on top for angry and fearful sentiment. The Torah stands out from the other texts due to the amount of disgust expressed therein. After Pride and Prejudice, the Bible uses the largest proportion of words that elicited emotions of anticipation.
There is still much more that may or may not be deduced from these cursory results. Most notably lacking from this analysis is any test for significant differences. The reason for that being that I am not interested in supporting any sort of argument for differences between these texts. With n values (word count) in excess of 3,000 significant differences between the different texts is almost guaranteed as well so any use of a p-value here would just be cheap p-hacking anyway.